



 币圈观察
币圈观察
头条|ees:给 AI 讲故事,如何教它脑补画面?
摘要:阿里妹导读:视觉想象力是人与生俱来的, AI 能否拥有类似的能力呢?比如:给出一段故事情节,如何让机器展开它的想象力,“脑补”出画面呢?看看阿里AI Labs 感知实验室的同学们如何解决这个问题。阿里
阿里妹导读:视觉想象力是人与生俱来的, AI 能否拥有类似的能力呢?比如:给出一段故事情节,如何让机器展开它的想象力,“脑补”出画面呢?看看阿里AI Labs 感知实验室的同学们如何解决这个问题。

阿里妹导读:视觉想象力是人与生俱来的, AI 能否拥有类似的能力呢?比如:给出一段故事情节,如何让机器展开它的想象力,“脑补”出画面呢?看看阿里AI Labs 感知实验室的同学们如何解决这个问题。
1. 背景 —— 视觉想象力(Visual Imagination)
1.1 什么是视觉想象力?
视觉想象力是人脑拥有的一个重要功能,可以将一些抽象的概念具象化,进而凭借这些视觉想象进行思考。如图1最左列,当我们想到:A yellow bird with brown and white wings and a pointed bill时,脑海里可能已经想象出了一幅黄色鸟的画面。这就是视觉想象力。我们的目标就是让AI逐步具备这种能力。

图1:由第一行中的文本描述,AI“想象”出的画面 [1]。
1.2 AI拥有视觉想象力后的影响?
AI如果具备视觉想象力后,将会更懂人的需求,并能够对一些传统行业产生颠覆性影响。下面举两个例子。
图2为一个在语义图像搜索领域中的案例。我们在google中搜索man holding fish and wearing hat on white boat,可能返回的结果质量为(a),引擎只是零星理解了我们的搜索意图。而当机器拥有一定视觉想象力后,它的搜索结果可能是(b),这将极大提升我们的信息检索效率,而这些信息是承载于图像中的。

图2:AI具备视觉想象力后将会对语义图像搜索产生重要影响 [2]。
另一个例子在语义图像生成领域。试想:当我们用语言描述一个场景时,机器利用其庞大的经验数据便自动生成了这个场景。如图3,如果我们描述一个人拥有不同的外貌特征,那机器便自动想象出了这个人的样貌,这将对诸如刑侦等领域(如受害人描述犯罪分子样貌)产生怎样的颠覆。

图3:AI具备视觉想象力后将会对语义图像生成产生重要影响 [3]。
2. 选题 —— 站在巨人的肩膀上
2.1 领域的痛点在哪?
我们将焦点移至文本生成图像(text-to-image synthesis)领域。此领域中,针对简单单一主体的图像生成,例如:鸟、花、人脸等,利用GAN的思想而来的一系列算法已经取得了一些令人欣喜的结果,如图1。然而,当文本中含有多个相互关联的物体时,生成的效果就会大打折扣,如下左图所示。这主要是由过于灵活、非结构化文本所造成的。
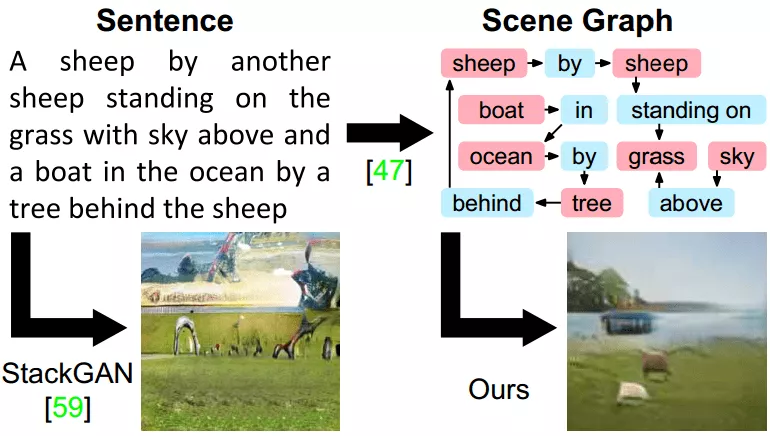
图4:当前的生成算法很难对包含多个相互作用的物体进行生成,如左边的StackGan算法 [4]。右边的sg2im算法则一定程度上拥有潜力解决这个问题 [5]。
因此,Stanford大学CV组的Johnson等人在CVPR2018中提出了将文本到图像的生成拆分为若干个更加可控的子问题的想法 [5]。这用到了他们之前在CVPR2015中提出的一种新的场景表达方式 —— 场景图(Scene Graph)和语义构图(Semantic Layout) [2]。
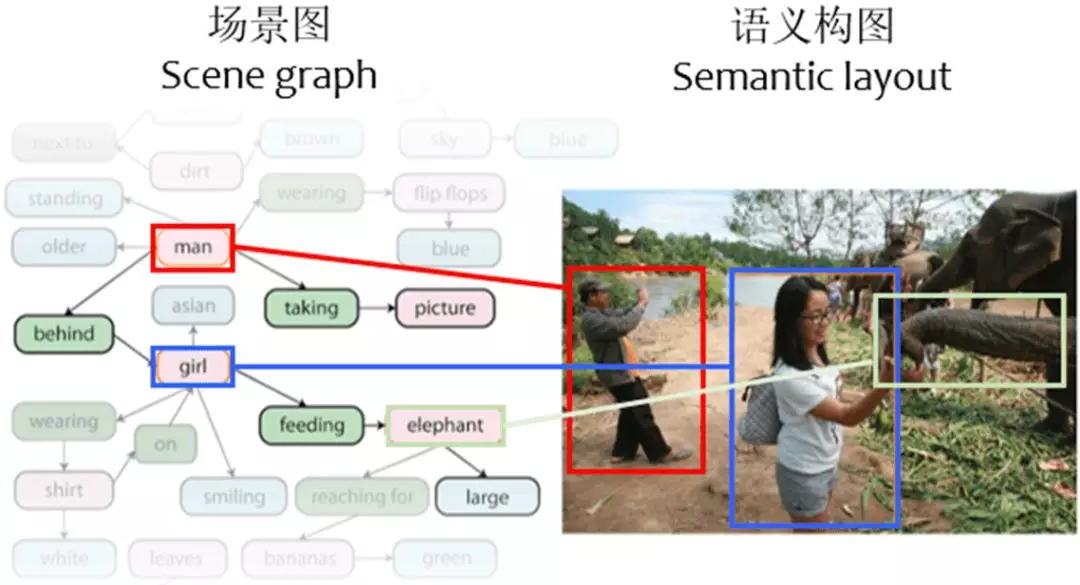
图5:场景图和语义构图示意 [6]。
场景图是一种有向图,含有实体、属性、关系三种要素,可以看做是一种语义模态下的结构化表达。
每个场景图中的实体,在图像中会有一个与之对应的bbox。如果不看图像本身,单看图中所有的bbox,就形成了一幅图像的语义构图,因此可以将语义构图看作是一种具有普遍含义的图像结构化表达。
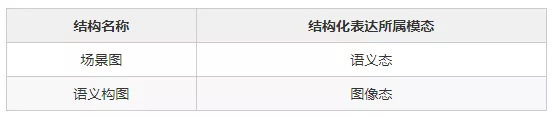
表1:结构名称及所属模态对照表。
2.2 如何解决?—— 我们眼中的大框架
站在大牛们的肩膀上,我们眼中从文本到图像的生成大致分为下面几个子任务:

表2:由文本生成图像任务拆分而来的子任务列表。
为了达到可控生成,信息逐步升维的目的,整个过程大致可拆分为上述子任务。每个子任务都有相应的一些工作,在此不一一具体展开。
2.3 论文的关注点
论文专注于解决子任务3:如何由场景图生成场景构图?
这个任务之所以重要,是因为由这个任务而始,结构化语义态的信息得以“想象”为图像的结构化表达,是赋予机器以视觉想象力的关键所在。
3. 论文的动机及贡献
3.1 当前的问题
| 3.1.1 最接近的工作与组合爆炸问题
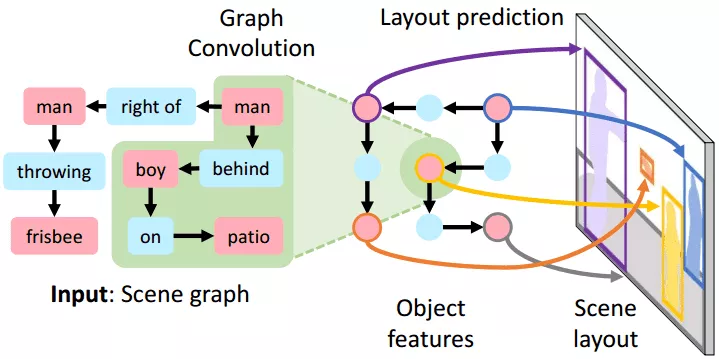
图6:sg2im利用图卷积网络,以场景图整体作为输入,生成语义构图整体 [5]。
最接近的工作来自Stanford Johnson等人在CVPR2018中发表的sg2im算法 [5](如图6)。他们首先利用一个图卷积网络将每个实体进行特征嵌入,继而用这些特征通过一个object layout网络去生成语义构图。他们采用的生成方式是由场景图整体到语义构图整体。场景图整体中会包含若干个实体和关系,这些实体和关系的组合所形成的场景图变化极多,使得模型难以有效表达如此多的变化,最终导致了语义构图学习效果的不理想。我们称之为组合爆炸问题。
| 3.1.2 语义构图评价指标的缺失
另一大挑战是:如何直接自动化评价语义构图生成的好坏?
过去绝大部分工作采用间接自动化评价的方式进行,对由语义构图生成后的图像给予打分,利用Inception score或Image captioning score。这样做根本无法评价语义构图的生成好坏,很大程度上只评估了最终的GAN网络是否有效。很多工作还加入了人工评分,虽给出了评分结果,但其几乎不可能被完全复现,这极大地阻碍了本领域的发展。
3.2 Seq-SG2SL的动机
Seq-SG2SL是我们针对组合爆炸问题提出的一个由场景图生成语义构图的框架。本节不谈框架本身,先讲个故事。
故事背景:老师需要教学生学习如何通过看建筑图纸去建楼。如图7。

图7:上图是建筑图纸示意,下图是建成的房间示意(图片来源于网络)。
A老师教快班。他指着一摞厚厚的图纸对学生们说:“看,这是之前的图纸,上面有按图纸建好的大楼地址,你们拿这些图纸去看看那些大楼,应该就能悟出来大楼是怎么建的了。以后我给你一张新图纸,你们就能建出大楼了。”学生们按照A老师的方法,纷纷去学了。当A老师测验时发现,几乎没有学生可以照图纸盖出大楼,A老师生气地说:“还快班呢,这群学生也太没有悟性了,举一反三都不会。”
B老师教慢班。他对学生们说:“我给大家一些图纸,今天我先教大家怎么建客厅,明天教怎么建厨房。我们的目标是先把每个房间的建造套路学到,再教大家怎么串起来建一整间房。最后再教你们怎么建栋楼。看看这些图纸,不必着急,我会告诉你们每一部分都和实际建筑里的哪一部分相对应,虽然整栋建筑看起来都不一样,但这些局部是很有套路的,掌握以后保管你们都会盖大楼。”果然,在B老师的悉心教导下,所有同学都很快通过了测验,连小笨笨源方都学会了怎么看图纸建大楼。
故事中,A老师的学生虽然是快班的,都很聪明,但是大楼千变万化,学生们通过这些图纸很难学到其中的共性。而B老师的学生,虽然整体学习比较慢,记性也不好,但B老师通过教授建大楼所需要的一些基础知识,将这些具有共性的要点教给学生,结果笨鸟得以先飞。
场景图就好比建筑图纸,语义构图就好比大楼。A老师的教学方法其实就遇到了组合爆炸的问题,B老师通过教授最基础的建楼操作避免了组合爆炸的问题。
由此启发,我们提出了一种全新的视角,去看待由场景图生成语义构图的问题。语义构图是一个结果,我们要学习的不应该是直接这个结果,而是产生这个结果的过程。通过对更基础单元的学习,解决组合爆炸问题。
3.3 SLEU的动机
为了解决缺乏直接自动化评估指标的问题,我们提出了一个新指标:semantic layout evaluation understudy,简称SLEU。这个指标是受到著名的机器翻译指标BLEU启发而来。
背后的逻辑是这样的:
1)要想完成自动化评估,必须需要真值。
2)SLEU的设计目的就是要度量一个生成的语义构图与真值之间的差异。
因此,遵循上述逻辑,我们类比了机器翻译指标BLEU的设计,将BLEU的基本概念由1D扩展到2D,提出了SLEU。
3.4 论文的贡献
1)提出了一个新的框架Seq-SG2SL,将语义构图看作是一系列过程叠加的结果。和以往方法不同,AI学的是生成过程而不是结果。这种序列到序列的学习方式可以解决组合爆炸问题。
2)提出了一个直接自动化评价语义构图生成好坏的指标SLEU,将会解决本领域存在的结果复现问题,为不同构图生成方法的直接比较提供基础。
4. 方法要点简述
4.1 Seq-SG2SL框架
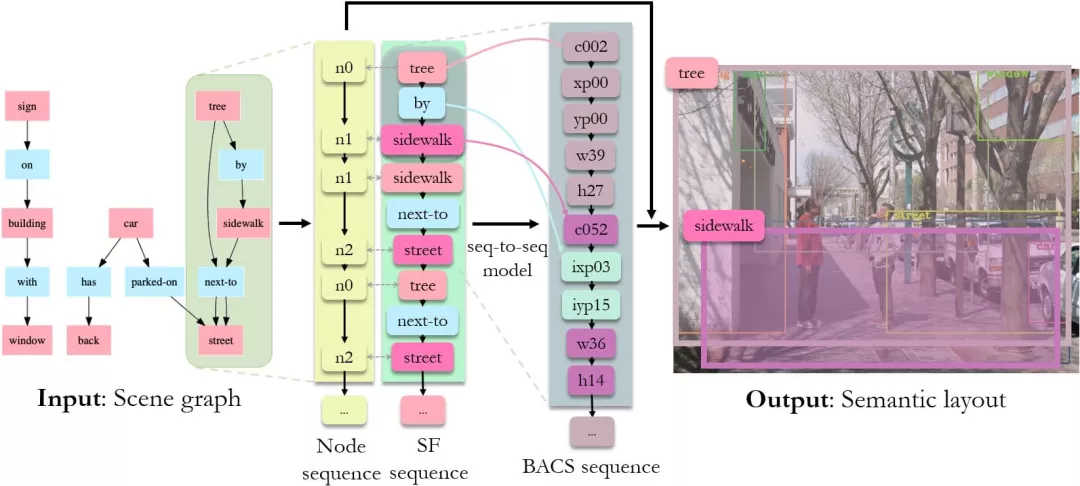
图8:Seq-SG2SL框架。
什么决定了一张语义构图呢?是关系。因此,一个场景图中的关系三元组(主 - 谓 - 宾),决定了组成一张语义构图中的主语和宾语所对应的两个bbox。其中主语和宾语所对应的bbox,分别称为视觉主语(visual subject)和视觉宾语(visual object)。
由此,产生语义构图的过程可拆解为一系列基础动作片段,每一个基础动作片段称为一个brick-action code segments (BACS)。每一个BACS执行的操作就是将一个视觉主语和一个视觉宾语摆放到语义构图中,分别调整他们的类别,位置以及大小。而每一BACS恰恰由其在场景图中所对应的关系三元组所决定。一个关系三元组主-谓-宾顺序相接,三个词组成了一个基础语义片段,我们叫做一个semantic fragments(SF)。如图8,tree by sidewalk就是一个SF,它对应的图中BACS Sequence所示的那10个code(c0002 … h14)就是一个BACS,而这10个code执行的结果就是最右侧layout图中tree和sidewalk两个bbox。
将一系列SF进行串联,形成了SF序列(SF sequence)。这个SF序列所对应的是一个由每一个对应BACS所串联形成的序列(BACS sequence)。这两个序列,就像两种语言,我们需要做的只是让机器学习从SF语言“翻译”到BACS语言就好啦。当然,为了保有scene graph中的有向图信息,我们额外维护了一个节点序列(Node sequence),主要为了确定sequence中的哪些实体属于同一个实体,并且能够通过节点序列直接将场景图中的实体属性传递到语义构图中的bbox上。这样,整个Seq-SG2SL框架做到了灵活且通用。
回想一下,这个过程是不是像我们之前讲过的那个老师教学生从设计图纸建楼的故事。我们看到了设计图纸(scene graph)中的一个局部(一个SF),然后我们去学习大楼(semantic layout)中的这个对应局部是怎么建的(学习一个BACS),最后再综合,教学生去建整幢建筑。这样做是不是很直观,也符合客观规律,我们不要求我们的学生(模型)都是天才般的存在,但是需要我们这个老师教授方式得法,才能最终达到好的效果。
框架的主要思想就讲完了,细节的话感兴趣的读者可以去看论文。
4.2 SLEU指标
在介绍SLEU之前,我们希望读者已经熟悉什么是机器翻译中的BLEU指标。
BLEU的基础是n-gram。n-gram是指文本中连续出现的n个词语(word),是基于(n-1)阶马尔科夫链的一种概率语言模型。简单地说,其假设当前第n个词出现的概率,仅取决于其前(n-1)个词,而跟更前的词无关。在机器翻译中,BLEU评估的基本单位是word,一个unigram代表一个word,评估翻译的充分性,而较长的n-gram代表一个word序列,评估翻译的流畅性。BLEU的思想是将句子拆分为n-grams,评估局部相似度,进而对整体翻译效果进行打分。
对于机器翻译而言,最小可拆分单元是一个word,那对于语义构图生成问题而言,最小可拆分单元又是什么?是一个关系。因此,对于语义构图生成来说,我们的unigram变为了一个关系。评估充分性就是评估单个关系是否匹配;评估流畅性就是评估n个关系是否会同时匹配。我们同样做了n阶马尔科夫链的假设,即:一个关系的出现,只取决于不超过(n-1)个其他关系,而和更多的关系无关。由于场景图和语义构图中的物体是一一对应的,因此没有precision和recall的概念,我们称对单个关系的评估,叫做unigram accuracy,而对多个关系的评估叫做n-gram accuracy。
具体设计我就不在这里细讲了,将关系看做unigram是我们的核心思想。我们的工作只是将这个概念设计出来,将BLEU的概念由1D推广到2D罢了。感兴趣的读者可以参考论文,指标的实现也将会开源。
5. 实验结果预览
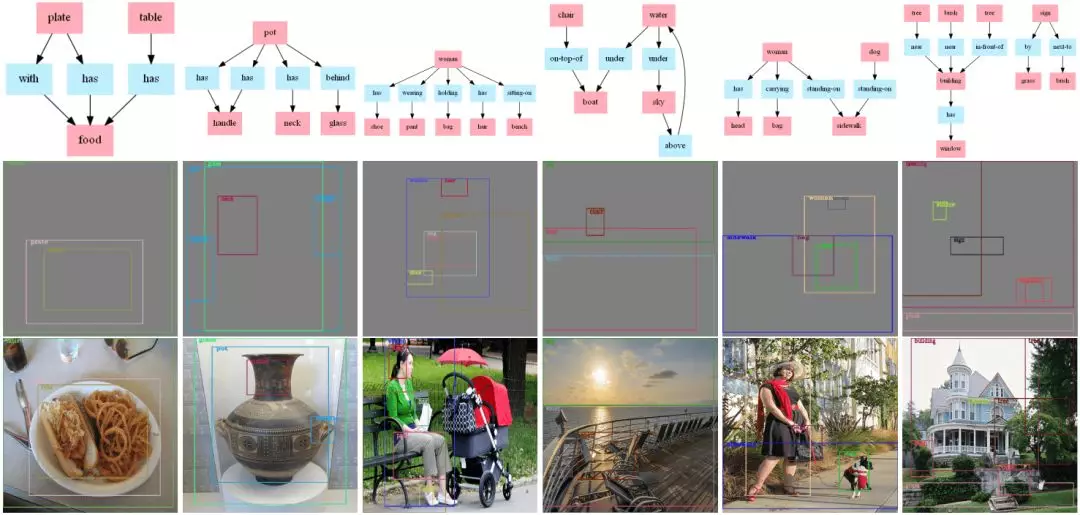
图9:由Seq-SG2SL框架在测试集上的一些结果展示。
上图是一些利用Seq-SG2SL在测试集上的生成的结果,其中第一行为输入,第二行为生成的语义构图,第三行是一个参考的语义构图及其对应图像。可以看出,我们的结果可以对含有多个关系的复杂场景进行构图生成。
原文链接:https://yq.aliyun.com/articles/727420?utm_content=g_1000088037
本文为云栖社区原创内容,未经允许不得转载。
- 免责声明
- 世链财经作为开放的信息发布平台,所有资讯仅代表作者个人观点,与世链财经无关。如文章、图片、音频或视频出现侵权、违规及其他不当言论,请提供相关材料,发送到:2785592653@qq.com。
- 风险提示:本站所提供的资讯不代表任何投资暗示。投资有风险,入市须谨慎。
- 世链粉丝群:提供最新热点新闻,空投糖果、红包等福利,微信:juu3644。





